How we built opengazettes.org.za

How we built opengazettes.org.za
Before we could build Open Gazettes South Africa, we needed to figure out what additional value we could provide by putting the resource together. By building a series of programs used to source, scrape and index government gazettes, we now have a growing collection of over 12,000 free and searchable publications.
Government gazettes are valuable entities in and of themselves. They’ve been consumed, published and archived in this form for centuries; their style, language and appearance more suited to newspaper adverts than modern information dissemination.
Currently, government gazettes still look like they’re produced on the printing presses of the 1800s. Their text flows neatly from page to page, and whether it’s a 50-word liquidation notice or a 400-page green paper, it will be published in the same format as gazettes always have been.

This is why before building the Open Gazettes resource, we needed to have some idea of what additional value we could provide. The majority of people who use gazettes tend to be lawyers, librarians and special interest groups. So we asked ourselves, “How can gazettes be made available to the general public in a way that helps them to participate in policy-making and governance?”
While they may be beautiful pieces for print, the real question is what South Africans need today. Journalists, civil society and concerned citizens need access to gazettes to monitor, communicate, investigate and hold the government to account.
Our long-term goal is to extract as much information relevant to accountability as possible as structured data that we can slice and dice, search and connect with others. People should be able to track and be notified when a piece of legislation that is relevant to them is gazetted and open to public comment - this could be achieved through a simple SMS or email. Those who want to know when Eskom wants to sneak a nuclear power plant into their backyard could at the least expect a phone call about it. Those who want to find the connection between their brother and the Guptas shouldn’t have to sit in a public library paging through thousands of documents.
Instead, they should be supported in finding potential connections via common business partners and dealings by simply entering their names into a search function.
Getting gazettes
Today, government gazettes are made available by the national and provincial government as PDF documents containing searchable text. Everyone except the Free State makes their gazettes available online, free of charge. We wrote a couple of computer programs, called web scrapers, to find and download gazettes from the Government Printing Works (GWP) and Western Cape Government websites where they are released publicly. These run daily to find new gazettes as they are published, and store them online. This uses the Scrapy platform, which makes sure we only download files once. Below is an example of Python code to scrape the GWP for gazettes:
class GpwSpider(scrapy.Spider):
name = "gpw"
allowed_domains = ["gpwonline.co.za"]
start_urls = {
'http://www.gpwonline.co.za/Gazettes/Pages/Provincial-Gazettes-Eastern-Cape.aspx',
...
}
def __init__(self, start_url=None):
if start_url is not None:
self.start_urls = [start_url]
def parse(self, response):
gazette_row_css = '.GazetteTitle'
for row in response.css(gazette_row_css):
gazette_item = GazetteItem()
label_xpath = 'div/a/text()'
gazette_item['label'] = row.xpath(label_xpath)[0].extract()
file_urls_xpath = 'div/a/@href'
gazette_item['file_urls'] = row.xpath(file_urls_xpath).extract()
date_xpath = 'div/text()'
gpw_pub_date = row.xpath(date_xpath)[0].extract()
date = datetime.strptime(gpw_pub_date, '%d/%m/%Y')
gazette_item['published_date'] = date.isoformat()
gazette_item['referrer'] = response.url
yield gazette_item
next_page_xpath = '//div[@class="Paging"]/div/strong/following-sibling::a/@href'
next_pages = response.xpath(next_page_xpath)
if next_pages:
yield scrapy.Request(urlparse.urljoin(response.url, next_pages[0].extract()))
But this is just the beginning. The gazettes are a record of so many formal events that have ongoing impact. A comprehensive archive of recent and historical gazettes can help understand how our land ended up being used the way it is, as well as many relationships between business and government.
To build a comprehensive archive, we are looking to all the possible sources of older gazettes. It would be very resource-intensive and take rather long to scan all government gazettes that are available in our libraries - besides, sourcing older gazettes is particularly difficult. In addition to scanning, we need to use something called Optical Character Recognition (OCR) to be able to search the text and find structure in the print.
Indexing and gazette references
Once we actually have the gazettes, we need to make sure people can refer to them in a standard way. For example, someone might want to refer to exemptions introduced by the Financial Services Board and cite the relevant gazette as Government Gazette volume 471, number 26844. To support looking up gazettes using that common reference in our archive, we need to index them according to the series numbering used for that particular gazette. This is slightly complicated because different sources and provinces have different indexing systems.
We have another program that runs nightly after scraping new gazettes, uniquely identifying and storing them in our archive. This also updates the computer-readable index and feed of new gazettes, and triggers the Open Gazettes site to be updated with the latest editions. This is a simple static website built using Jekyll. We use TravisCI to build it from some templates and the latest index file.
By making the gazette sourcing, indexing and archiving flexible, we can source old and new gazettes from several sources at once. If we simply went ahead and start scanning gazettes en mass, it’s not clear how much metadata - like the title, issue and volume number - will accompany them. This is why we use various programs to do this for us.
While this allows us to create good-looking lists of government gazettes on a website, it doesn’t really give users anything they didn’t already have; this was just the foundation to build more user-friendly ways of accessing the information that gazettes contain. Our next step was to figure out what would set Open Gazettes apart: the search function.
Search inside gazettes
While Google and DocumentCloud do a reasonable job of making these types of documents searchable, they didn’t provide the user experience we believe is needed. So we decided to utilise the Aleph project. This provides a website that supports gathering and searching documents, and identifying entities like companies and people.
In addition to searching for something - for example, “driving permit paarl” - you can set an alert so that you’re notified by email within a few days of when a gazette matching the search is published. This means that you don’t need to check each week for new information, such as newly issued permits in your area.
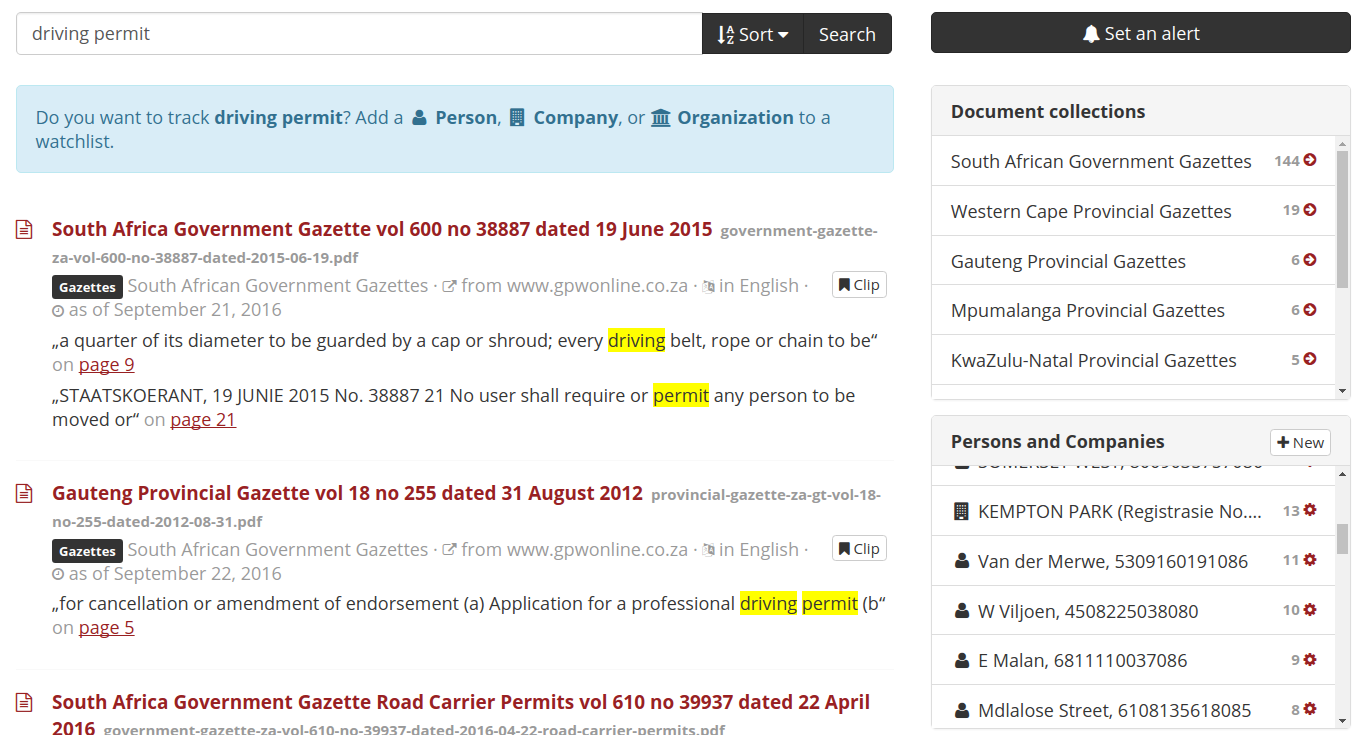
Aleph uses the text embedded in the gazette PDF files to support text search. While PDFs look like text documents, they’re mostly focused on looking good and do not necessarily contain text in a form that is usable by a computer. To make a scanned PDF searchable, the text found using OCR (Optical Character Recognition) is overlaid on the image in the PDF.
Once Aleph has ingested a document and analysed the text, it’s available to search and jump straight to the page containing the information that you’re looking for.
What’s next?
Our next step is to extract structured data, focusing primarily on data that can help link corporate entities to identify evidence of corruption. When gazetted information can easily be linked to public databases like the company register, political candidate lists and Johannesburg Stock Exchange notices, we can truly approach the accountability our legal system has tried to foster. We’ve already started identifying South African ID numbers and company registration numbers from CIPC using entity extractors in Aleph. We also want to connect these with the organisations these entities deal with, which industries they operate in and the geographical addresses where they operate. Some semi-regular sources of this information in the gazettes include: -Tender bids and awards -Company liquidation notices -Liquor license applications -Business and personal name changes
The fact that machine-readable text isn’t the primary focus of PDFs does make it more difficult than it needs to be to use this information to hold individuals and entities to account. We decided to approach the GPW to address the issue of text being mangled when placed in a PDF; it makes reliable extraction incredibly difficult. When asked if we could get access to notices in the form in which they are submitted, Bonakele Mbhele, the Chief Director of Marketing and Stakeholder Relations, raised the concern that many people have with their personal information being made public:
“The gazettes are published by GPW in the PDF format to preserve and ensure accuracy of the publication as legal government communication,” she explains. “Releasing these publications in open files format would open them to abuse where the original information may be changed to suit the requirements of the perpetrator.”
But we feel the argument that they shouldn’t be published in a better format for privacy isn’t sufficient because we can - and are already - extracting it for good; for the sake of accountability.
However, there are various pieces of legislation that stipulates this information - such as a name change - be made public in the Government Gazette. Of course the misuse of personal information in gazettes is a valid concern, but this has been the case for over a century now and at the end of the day, the information is available via gazettes. Continuing to publish gazettes only in badly-machine-readable forms only hurts accountability.
As part of our #GazetteLiberation campaign we are looking to engage with as many organisations and concerned citizens as possible. If you or anyone you know of has ideas or experience with sourcing, indexing and scraping structured data from publications like government gazettes, please get in touch via our discussion portal or send us an email on gazettes@code4sa.org.